






Cardano’s Hoskinson Takes a Break as ADA Falls Below $0.20 After Five Years
On 3 June 2026, Charles Hoskinson, the founder of Cardano and head of Input Output Global, announced that…

Why more women are choosing natural lash extensions for everyday beauty
Beauty trends come and go, but the treatments that truly stay relevant are usually the ones that make…

What Is Xcelerate Trade and Why Is It Gaining Attention Among Online Traders?
There is a kind of quiet energy that surrounds a new trading platform when it starts showing up…

Waxing vs. Shaving: The truth about smooth skin
Smooth, touchable skin never goes out of style — but how you achieve it makes all the difference.…

Sonic vs. Fantom: Key Differences, Market Impact, and Future Price Evolution
In the dynamic realm of cryptocurrencies, understanding the evolution of blockchain platforms is crucial for both enthusiasts and…

How Can I Add Personality to My Home Decor
Creating a home that reflects your personality is one of the most rewarding aspects of interior design. A…

Why Are SEO Articles More Effective Than Paid Ads
Businesses and marketers continuously search for the best strategies to attract customers and generate revenue. In this context,…

How to combine new school tattoos with other tattoo styles
If you’re a tattoo enthusiast or contemplating getting your first ink, you’ve probably come across various tattoo styles…
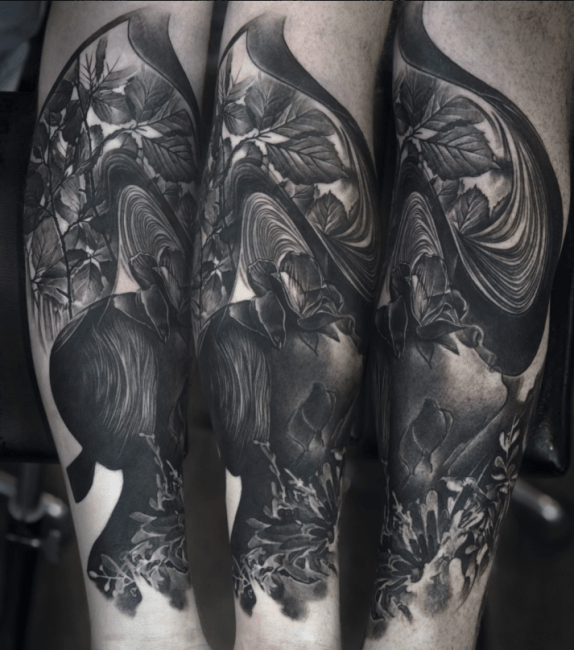
Unveiling the Power of Black Tattoos: A Bold and Personal Expression
In the vast, dynamic world of tattoo artistry, black tattoos stand distinct with a grace and subtlety of…
The benefits of economy rent a car
Whether you’re on vacation and need to get around town, or you just don’t have access to your…

How to plan your vacation in Transylvania?
Have you been planning a trip to Transylvania for a long time but have never made it to…

Mental attitude before falling asleep – Sleeping routine for better sleep
Insomnia and sleep disorders can be associated with stress and other factors (such as medications) that, according to…

The Value Of Visual Arts In Schools
Graphic arts are a-class of art-forms offering: photography, statue, artwork, along with other professions that concentrate on the…
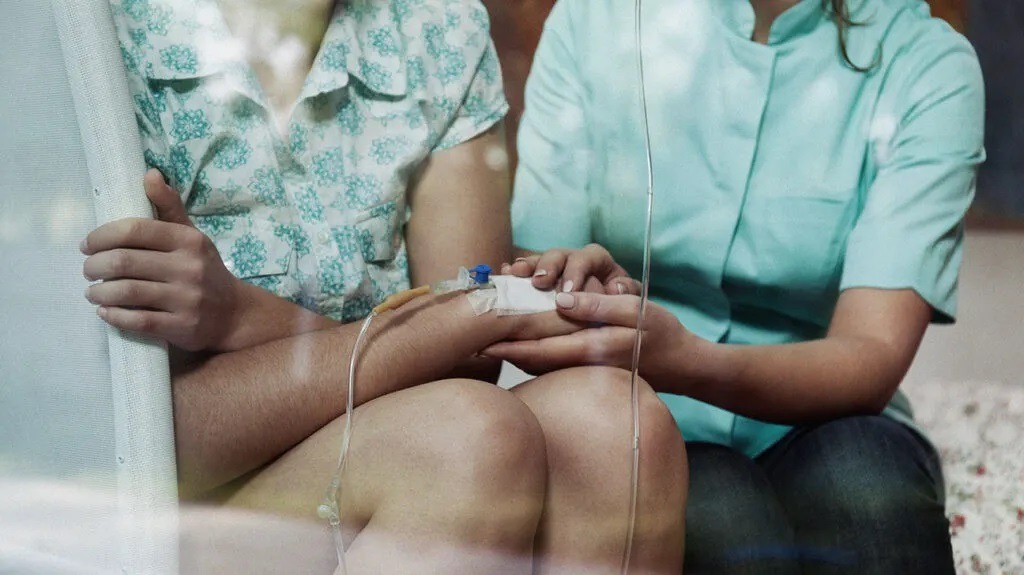
Tips For Preparing For and Recovering From Surgery For Cancer
If you are facing a surgical procedure to treat cancer, you may be understandably afraid. The fact is,…

Getting Your Traffic from Free Sources
One of the first things you need to learn about affiliate marketing is that traffic is the life…

Baking with coconut oil
Use high quality, organic coconut oil for delicious and healthy baked goods. Coconut oil is gaining more and…

Is Working As An HGV Driver Flexible?
Heavy goods vehicle (HGV) drivers are an essential part of the logistics industry. Without them, we wouldn’t be…

Best things to do in Mures county
Wondering what would be the best things to do in Mures county? So here we go. Mureș county…

The freedom of living in a tiny house
The small living trend is a trend that is spreading in overcrowded cities around the world, so also…

What qualities do I need to become a web designer
Website designers are often concerned with their tangible skills, such as Photoshop skills or a mastery of jQuery.…